Running a cluster with Apache Nifi and Docker
If you don’t want the details behind Nifi’s clustering, you can skip ahead to running a cluster.
Clustering Apache nifi has multiple benefits that come along with the complications it introduces, the main benefit being more throughput and data processing power. If you’ve run a single machine instance of nifi before, you know that having data intense processors running can take a hit on all of your resources depending on the type of tasks you are doing. We’ve maxed CPU with CSV/JSON parsing, IO with creating hundreds of thousands of records from gigabyte+ file ingestions, and RAM with large XML tree traversal that never seems avoidable. There are other ways to try and solve some of these resource issues (RAID, spanning repositories across disks, flow optimizations etc.), but one of the quickest ones is scale out horizontally, create a nifi cluster! With Nifi’s clustering, these tasks become more managable and you won’t look at your system stats wondering if everything will be ok… and it will, because we are here to help!
Nifi’s zero master clustering
We should start nifi’s clustering discussion with how it handles clustering. Apache Nifi, sicne release 1.0.0, decided to go the route of a zero master cluster paradigm. This was a change in direction from the initial 0.x releases which had a master-slave clustering paradigm. Zero master clustering allows for multiple benefits, the largest one being that Nifi is now responsive if a node (specifically the master node, or what they called the Nifi Cluster Manger, NCM) is lost. Previously, if the Master node died, the flows would continue (for the most part), but you could not see the flows, system stats, and it wasn’t accessible via the REST API. Soo… it was still working, but not entirely. I won’t go into too much more about why, but if you are curious I encourage you to read Nifi’s wiki article about Zero Master Clustering for more information and their reasoning behind moving to it. There is also some additional information online at Hortonworks blog.
Now that we’ve established why zero master, we should talk a little more about what that means for you the user/developer/system administrator/(your role here). With Nifi’s Zero master clustering, each node runs the same flow but over different data. At start up, Apache ZooKeeper randomly elects a Cluster Coordinator which the other nodes will send heartbeats and status information to. This coordinator is responsible for managing the cluster, disconnect nodes, new node additions, etc. If the Cluster Coordinator disconnects, ZooKeeper will elect a new one. This is just the basics to get us rolling, so again if you’d like more info I can’t recommend the Nifi documentation enough. It goes into really good detail about what is happening and is great for trouble shooting any issues you might run into (we are also here, if you need us).
Running a Cluster
So now that we know how nifi clusters and why we should cluster, let’s jump into running a cluster. We are going to start with a docker-compose file borrowed from the Apache Nifi repo and edit it to our needs. You can use this or recreate it to run a cluster across multiple machines.
docker-compose.yml: Nifi cluster compose
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
version: "3"
services:
zookeeper:
hostname: zookeeper
container_name: zookeeper
image: 'bitnami/zookeeper:latest'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
nifi:
image: apache/nifi:latest
ports:
- 8080 # Unsecured HTTP Web Port
environment:
- NIFI_WEB_HTTP_PORT=8080
- NIFI_CLUSTER_IS_NODE=true
- NIFI_CLUSTER_NODE_PROTOCOL_PORT=8082
- NIFI_ZK_CONNECT_STRING=zookeeper:2181
- NIFI_ELECTION_MAX_WAIT=1 minTo use this docker-compose.yml file and start up a cluster, we will run sudo docker-compose up --scale nifi=3 -d. This will start a cluster of 3 nifi nodes and one zookeeper container. We can then list the containers with docker ps, and you should see similar output to below.
Docker ps output
~/workspace/nifi-compose$sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ca94a7e52b36 apache/nifi:latest "../scripts/start.sh" 3 minutes ago Up 3 minutes 8443/tcp, 10000/tcp, 0.0.0.0:32779->8080/tcp nifi-compose_nifi_1
116ad3e0734b apache/nifi:latest "../scripts/start.sh" 3 minutes ago Up 3 minutes 8443/tcp, 10000/tcp, 0.0.0.0:32778->8080/tcp nifi-compose_nifi_3
dfba76bb1af9 apache/nifi:latest "../scripts/start.sh" 3 minutes ago Up 3 minutes 8443/tcp, 10000/tcp, 0.0.0.0:32777->8080/tcp nifi-compose_nifi_2
52f4193ff454 bitnami/zookeeper:latest "/app-entrypoint.sh …" 3 minutes ago Up 3 minutes 2181/tcp, 2888/tcp, 3888/tcp zookeeperWe set the nifi election period to a minute, so after at most a minute, we should be able to login to any 3 of the nodes. You’ll have to look at the docker ps, or docker-compose ps, output to grab the port mapping to login too. For me this time it was 32777, 32778, and 32779. Opening a browser to localhost:32779/nifi/, or any three of the ports you see should bring up nifi, showing three nodes connected, as below!
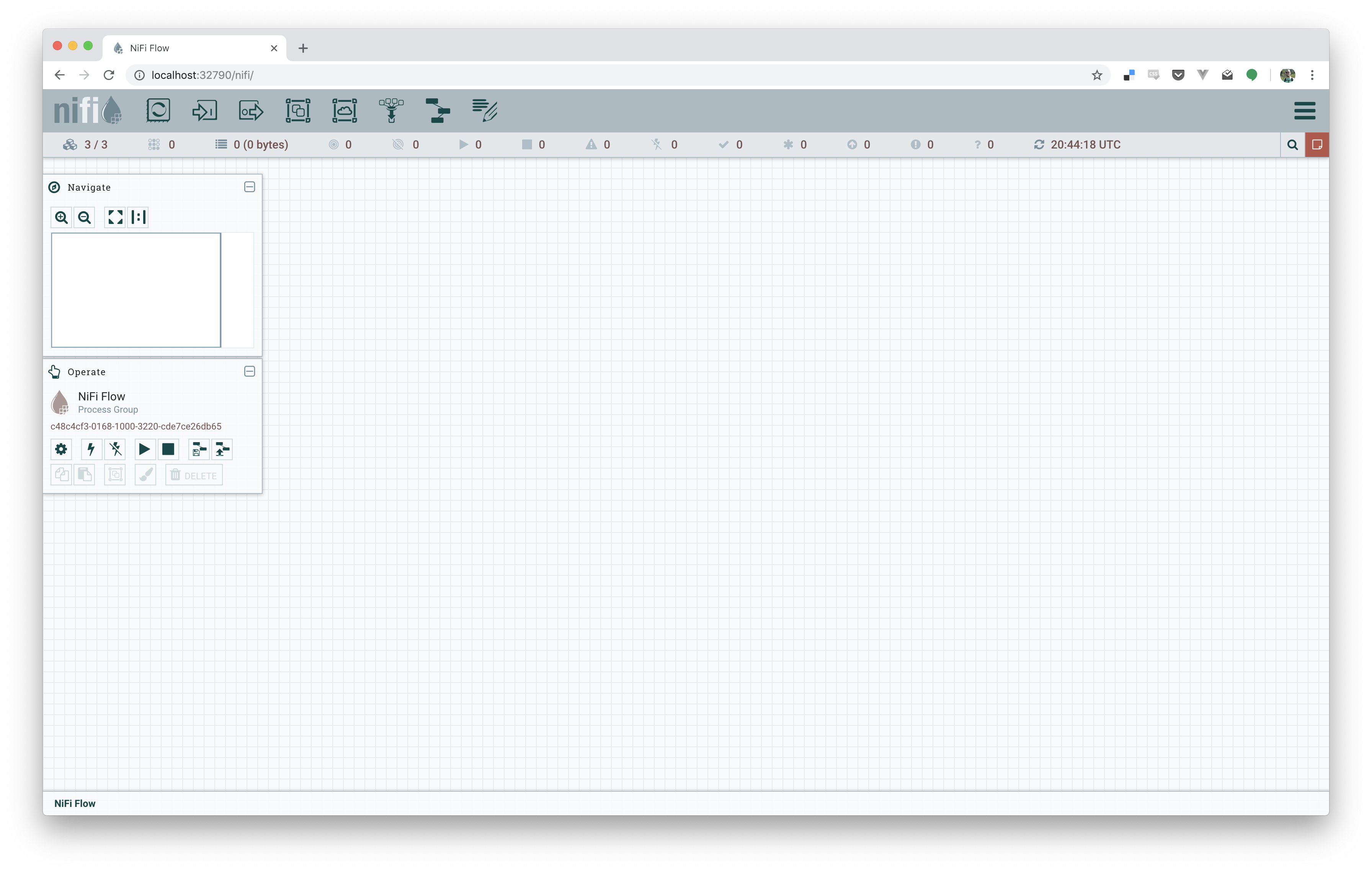
If all went well, you now have a basic cluster running! You can use docker-compose to scale up and down too; docker-compose up --scale nifi=4 -d to scale up to 4 nodes, docker-compose up --scale nifi=2 -d to scale down to 2 nodes, and so on.
This all works relatively well for a test cluster, but isn’t recommended for a produciton one of course. We’ll get around soon about how to take the nifi docker image and scale it up to a prod cluster with kubernetes, so keep an eye out for that post.